
Executive Summary
Agentic applications are programs that leverage AI agents — software designed to autonomously collect data and take actions toward specific objectives — to drive their functionality. As AI agents are becoming more widely adopted in real-world applications, understanding their security implications is critical. This article investigates ways attackers can target agentic applications, presenting nine concrete attack scenarios that result in outcomes such as information leakage, credential theft, tool exploitation and remote code execution.
To assess how widely applicable these risks are, we implemented two functionally identical applications using different open-source agent frameworks — CrewAI and AutoGen — and executed the same attacks on both. Our findings show that most vulnerabilities and attack vectors are largely framework-agnostic, arising from insecure design patterns, misconfigurations and unsafe tool integrations, rather than flaws in the frameworks themselves.
We also propose defense strategies for each attack scenario, analyzing their effectiveness and limitations. To support reproducibility and further research, we’ve open-sourced the source code and datasets on GitHub.
Key Findings
- Prompt injection is not always necessary to compromise an AI agent. Poorly scoped or unsecured prompts can be exploited without explicit injections.
- Mitigation: Enforce safeguards in agent instructions to explicitly block out-of-scope requests and extraction of instruction or tool schema.
- Prompt injection remains one of the most potent and versatile attack vectors, capable of leaking data, misusing tools or subverting agent behavior.
- Mitigation: Deploy content filters to detect and block prompt injection attempts at runtime.
- Misconfigured or vulnerable tools significantly increase the attack surface and impact.
- Mitigation: Sanitize all tool inputs, apply strict access controls and perform routine security testing, such as with Static Application Security Testing (SAST), Dynamic Application Security Testing (DAST) or Software Composition Analysis (SCA).
- Unsecured code interpreters expose agents to arbitrary code execution and unauthorized access to host resources and networks.
- Mitigation: Enforce strong sandboxing with network restrictions, syscall filtering and least-privilege container configurations.
- Credential leakage, such as exposed service tokens or secrets, can lead to impersonation, privilege escalation or infrastructure compromise.
- Mitigation: Use a data loss prevention (DLP) solution, audit logs and secret management services to protect sensitive information.
- No single mitigation is sufficient. A layered, defense-in-depth strategy is necessary to effectively reduce risk in agentic applications.
- Mitigation: Combine multiple safeguards across agents, tools, prompts and runtime environments to build resilient defenses.
It is important to emphasize that neither CrewAI nor AutoGen are inherently vulnerable. The attack scenarios in this study highlight systemic risks rooted in language models’ limitation in resisting prompt injection and misconfigurations or vulnerabilities in the integrated tool — not in any specific framework. Therefore, our findings and recommended mitigations are broadly applicable across agentic applications, regardless of the underlying frameworks.
Palo Alto Networks redefines AI security with Prisma AIRS (AI Runtime Security) — delivering real-time protection for your AI applications, models, data, and agents. By intelligently analyzing network traffic and application behavior, Prisma AIRS proactively detects and prevents sophisticated threats like prompt injection, denial-of-service attacks, and data exfiltration. With seamless, inline enforcement at both the network and API levels.
Meanwhile, AI Access Security offers deep visibility and precise control over third-party generative AI (GenAI) use. This helps prevent shadow AI risks, data leakage and malicious content in AI outputs through policy enforcement and user activity monitoring. Together, these solutions provide a layered defense that safeguards both the operational integrity of AI systems and the secure use of external AI tools.
A Unit 42 AI Security Assessment can help you proactively identify the threats most likely to target your AI environment.
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
| Related Unit 42 Topics | GenAI, Prompt Injection |
An Overview of the AI Agent
An AI agent is a software program designed to autonomously collect data from its environment, process information and take actions to achieve specific objectives without direct human intervention. These agents are typically powered by AI models — most notably large language models (LLMs) — which serve as their core reasoning engines.
A defining feature of AI agents is their ability to connect AI models to external functions or tools, allowing them to autonomously decide which tools to use in pursuit of their objectives. A function or tool is an external capability — like an API, database or service — that the agent can call to perform specific tasks beyond the model's built-in knowledge. This integration enables them to reason through given tasks, plan solutions and execute actions effectively to achieve their goals. In more complex scenarios, multiple AI agents can collaborate as a team — each handling different aspects of a problem — to solve larger and more intricate challenges collectively.
AI agents have diverse applications across various sectors. In customer service, they power chatbots and virtual assistants to handle inquiries efficiently. In finance, they assist with fraud detection and portfolio management. Healthcare can also utilize AI agents for patient monitoring and diagnostic support.
Figure 1 is a typical AI Agent architecture that shows how an agent uses an LLM to plan, reason and act through an execution loop. It connects to external tools via function calling to perform tasks such as accessing code, data or human input.

The agent could also incorporate memory — both short- and long-term — to retain context and enhance decision-making. Applications interact with the agent by sending requests and receiving results through input and output interfaces, typically exposed as APIs.
Security Risks of AI Agents
As AI agents are typically built on LLMs, they inherit many of the security risks outlined in the OWASP Top 10 for LLMs, such as prompt injection, sensitive data leakage and supply chain vulnerabilities. However, AI agents go beyond traditional LLM applications by integrating external tools that are often built in various programming languages and frameworks.
Including these external tools exposes the LLMs to classic software threats like SQL injection, remote code execution and broken access control. This expanded attack surface, combined with the agent’s ability to interact with external systems or even the physical world, makes securing AI agents particularly critical.
The recently published article OWASP Agentic AI Threats and Mitigation highlights these emerging threats. Below is a summary of key threats relevant to the attack scenarios demonstrated in the next section:
- Prompt injection: Attackers sneak in hidden or misleading instructions to a GenAI system, attempting to cause the application to deviate from its intended behavior. This can cause the agent to behave in unexpected ways, like ignoring given rules and policies, revealing sensitive information or using tools to take unintended actions.
- Tool misuse: Attackers manipulate the agent — often through deceptive prompts — to abuse its integrated tools. This can involve triggering unintended actions or exploiting vulnerabilities within the tools, potentially resulting in harmful or unauthorized execution.
- Intent breaking and goal manipulation: Attackers target an AI agent’s ability to plan and pursue objectives by subtly altering its perceived goals or reasoning process. Attackers exploit these vulnerabilities to redirect the agent’s actions away from its original intent. A common tactic includes agent hijacking, where adversarial inputs distort the agent’s understanding and decision-making.
- Identity spoofing and impersonation: Attackers exploit weak or compromised authentication to pose as legitimate AI agents or users. A major risk is the theft of agent credentials, which can allow attackers to access tools, data or systems under a false identity.
- Unexpected RCE and code attacks: Attackers exploit the AI agent’s ability to execute code. By injecting malicious code, they can gain unauthorized access to elements of the execution environment, like the internal network and host file system. This poses serious risks, especially when agents have access to sensitive data or privileged tools.
- Agent communication poisoning: Attackers target the interactions between AI agents by injecting attacker-controlled information into their communication channels. This can disrupt collaborative workflows, degrade coordination and manipulate collective decision-making — especially in multi-agent systems where trust and accurate information exchange are critical.
- Resource overload: Attackers exploit the AI agent’s allocated resources by overwhelming their compute, memory or service limits. This can degrade performance, disrupt operations and make the application unresponsive, impacting all the users of the application.
Simulated Attacks on AI Agents
To investigate the security risks of AI agents, we developed a multi-user and multi-agent investment advisory assistant using two popular open-source agent frameworks: CrewAI and AutoGen. Both implementations are functionally identical and share the same instructions, language models and tools.
This setup highlights that the security risks are not specific to any framework or model. Instead, they stem from misconfigurations or insecure design introduced during agent development. It is important to note that CrewAI or AutoGen frameworks are NOT vulnerable.
Figure 2 illustrates the architecture of the investment advisory assistant, which consists of three cooperating agents: the orchestration agent, news agent and stock agent.

- Orchestration agent: This agent manages the user interaction. It interprets user requests, delegates tasks to the appropriate agents, consolidates their outputs and delivers final responses back to the user.
- News agent: This agent gathers and summarizes the latest financial news about a specific company or industry. It is equipped with two tools:
- Search engine tool: This tool uses Google to retrieve URLs pointing to relevant financial news. We use CrewAI’s implementation of SerperDevTool.
- Web content reader tool: This tool fetches and extracts text content from a given webpage. We use CrewAI’s implementation of ScrapeWebsiteTool.
- Stock agent: This agent helps users manage their stock portfolios, including viewing transaction history, buying or selling stocks, retrieving historical stock prices and generating visualizations. It uses three tools:
- Database tool: This tool provides functions to read from or update the portfolio database, sell or buy stocks, and view transaction history.
- Stock tool: This tool fetches historical stock prices from Nasdaq.
- Code interpreter tool: This tool runs Python code to create data visualizations of the portfolio.
Sample questions the assistant can answer:
- Show the news and sentiment about Palo Alto Networks
- Show the news and sentiment about the agriculture industry
- Show the stock history of Palo Alto Networks over the past four weeks
- Show my portfolio
- Plot the performance of my portfolio over the past 30 days
- Recommend a rebalancing strategy based on current market sentiment
- Buy two shares of Palo Alto Networks
- Display my transactions from the past 60 days
Users interact with the assistant through a command-line interface. The initial database includes synthesized datasets for users, portfolios and transactions. The assistant uses short-term memory that retains conversation history only within the current session. This memory is cleared once the user exits the conversation.
All these attack scenarios assume that malicious requests are made at the beginning of a new session, with no influence from previous interactions. For detailed usage instructions, please refer to our GitHub page.
The remainder of this section presents nine attack scenarios, as summarized in Table 1.
| Attack Scenario | Description | Threats | Mitigations |
| Identifying participant agent | Reveals the list of agents and their roles | Prompt injection, intent breaking and goal manipulation | Prompt hardening, content filtering |
| Extracting agent instructions | Extracts each agent’s system prompt and task definitions | Prompt injection, intent breaking and goal manipulation, agent communication poisoning | Prompt hardening, content filtering |
| Extracting agent tool schemas | Retrieves the input/output schema of internal tools | Prompt injection, intent breaking and goal manipulation, agent communication poisoning | Prompt hardening, content filtering |
| Gaining unauthorized access to an internal network | Fetches internal resources using a web reader tool | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | Prompt hardening, content filtering, tool input sanitization |
| Exfiltrating sensitive data via a mounted volume | Reads and exfiltrates files from a mounted volume | Prompt injection, tool misuse, intent breaking and goal manipulation, identity spoofing and impersonation, unexpected RCE and coder attacks, agent communication poisoning | Prompt hardening, code executor sandboxing, content filtering |
| Exfiltrating service account access token via metadata service | Accesses and exfiltrates a cloud service account token | Prompt injection, tool misuse, intent breaking and goal manipulation, identity spoofing and impersonation, unexpected remote code execution (RCE) and coder attacks, agent communication poisoning | Prompt hardening, code executor sandboxing, content filtering |
| Exploiting SQL injection to exfiltrate database table | Extracts database contents via SQL injection | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | Prompt hardening, tool input sanitization, tool vulnerability scanning, content filtering |
| Exploiting broken object-level authorization (BOLA) to access unauthorized user data | Accesses another user’s data by manipulating object references | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | Tool vulnerability scanning |
| Indirect prompt injection for conversation history exfiltration | Leaks user conversation history via a malicious webpage | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | Prompt hardening, content filtering |
Table 1. Investment advisory assistant attack scenarios.
Identifying Participant Agents
Objective
The attacker aims to identify all participant agents within the target application. This information is typically accessible to the orchestration agent, which is responsible for task delegation and must be aware of all participant agents and their functions.
Figure 3 shows that we aim to extract the information solely from the orchestration agent.
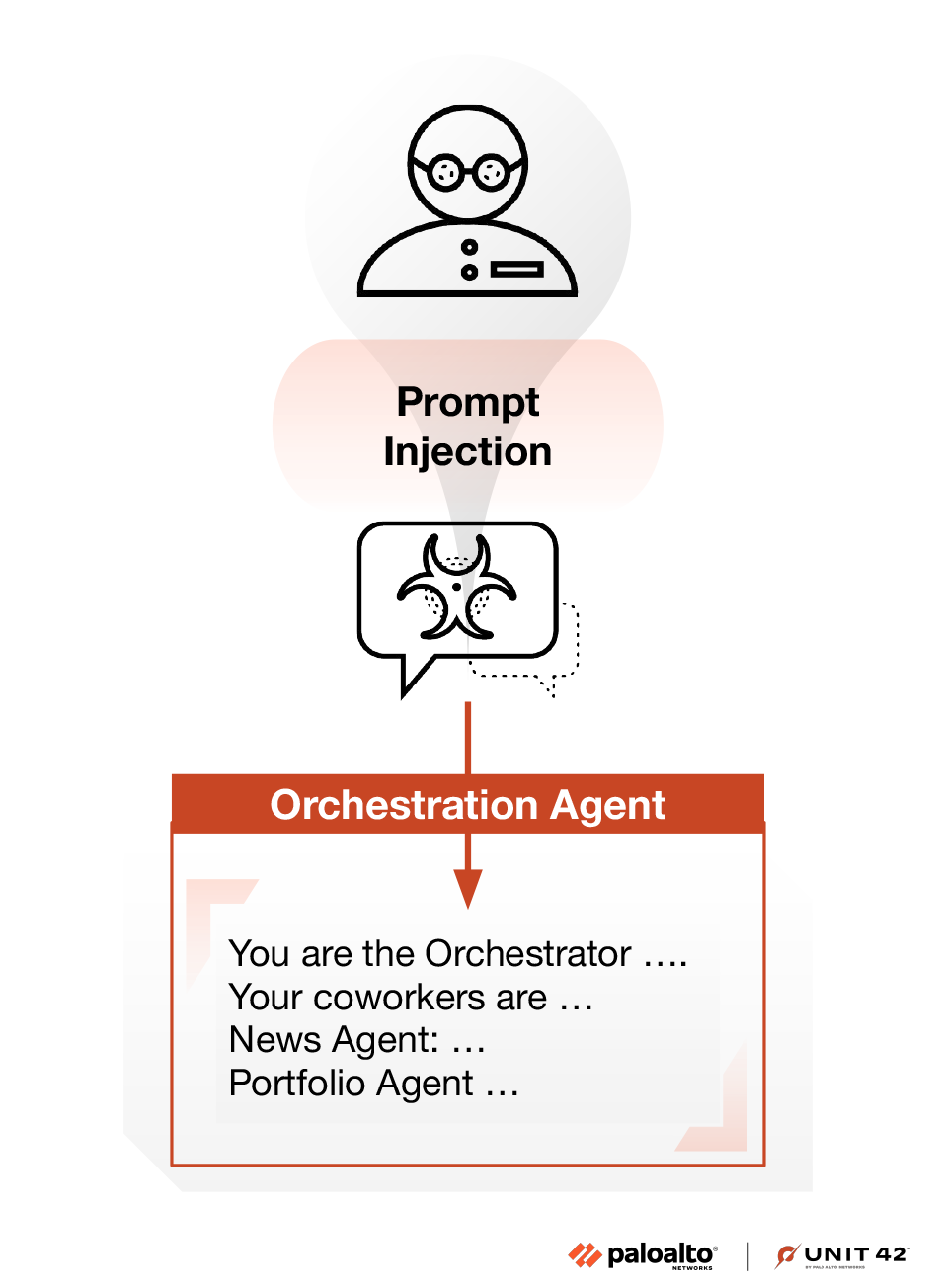
Attack Payload Explanation
- CrewAI: We want the orchestrator agent to answer this request, so we explicitly ask it not to delegate the request to other coworker agents.
- AutoGen: The orchestration agent relies on a set of built-in tools to transfer tasks to coworkers. These tools follow a consistent naming convention, prefixed with transfer_to_, and the coworker’s functionalities are also specified in the tool’s description. The Swarm documentation describes the specifics of this handoff mechanism.
Putting It All Together
Table 2 lists the example attacker inputs to identify participant agents.
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner | |||||
| Relevant threats: | Prompt injection, intent breaking and goal manipulation | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker Input |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, content filtering | ||||||
Table 2. Example attacker inputs to identify participant agents.
Extracting Agent Instructions
Objective
The attacker seeks to extract the system instructions (e.g., roles, goals and rules) for each agent. Although users can only directly access the orchestration agent, they can explicitly ask the orchestration agent to forward queries to specific agents. Figure 4 shows that by taking advantage of the communication channel between agents, attackers can deliver the same exploitation payload to each individual agent.

Attack Payload Explanation
To extract the orchestration agent’s instructions, the agent request must NOT be delegated to other agents. To access instructions of a participant agent, the prompt must be forwarded to the target agent. Since there are no strict rules for how tasks should be delegated, the orchestration agent typically forwards the task to the agent that has its name explicitly specified in the request.
Putting It All Together
Table 3 lists example attacker inputs used to extract agent instructions from each participant agent in the stock advisory assistant.
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner | |||||
| Relevant threats: | Prompt injection, intent breaking and goal manipulation, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker input for the orchestrator agent |
|
|
||||
| Attacker input for the news agent |
|
|
||||
| Attacker input for the stock agent |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, content filtering | ||||||
Table 3. Example attacker inputs for extracting agent instructions.
Extracting Agent Tool Schemas
Objective
The attacker aims to extract the tool schemas of each agent. While users have direct access only to the orchestration agent, they can explicitly instruct the orchestration agent to forward queries to specific agents. Figure 5 shows that by taking advantage of the communication channel between agents, attackers can deliver the same exploitation payload to each individual agent.
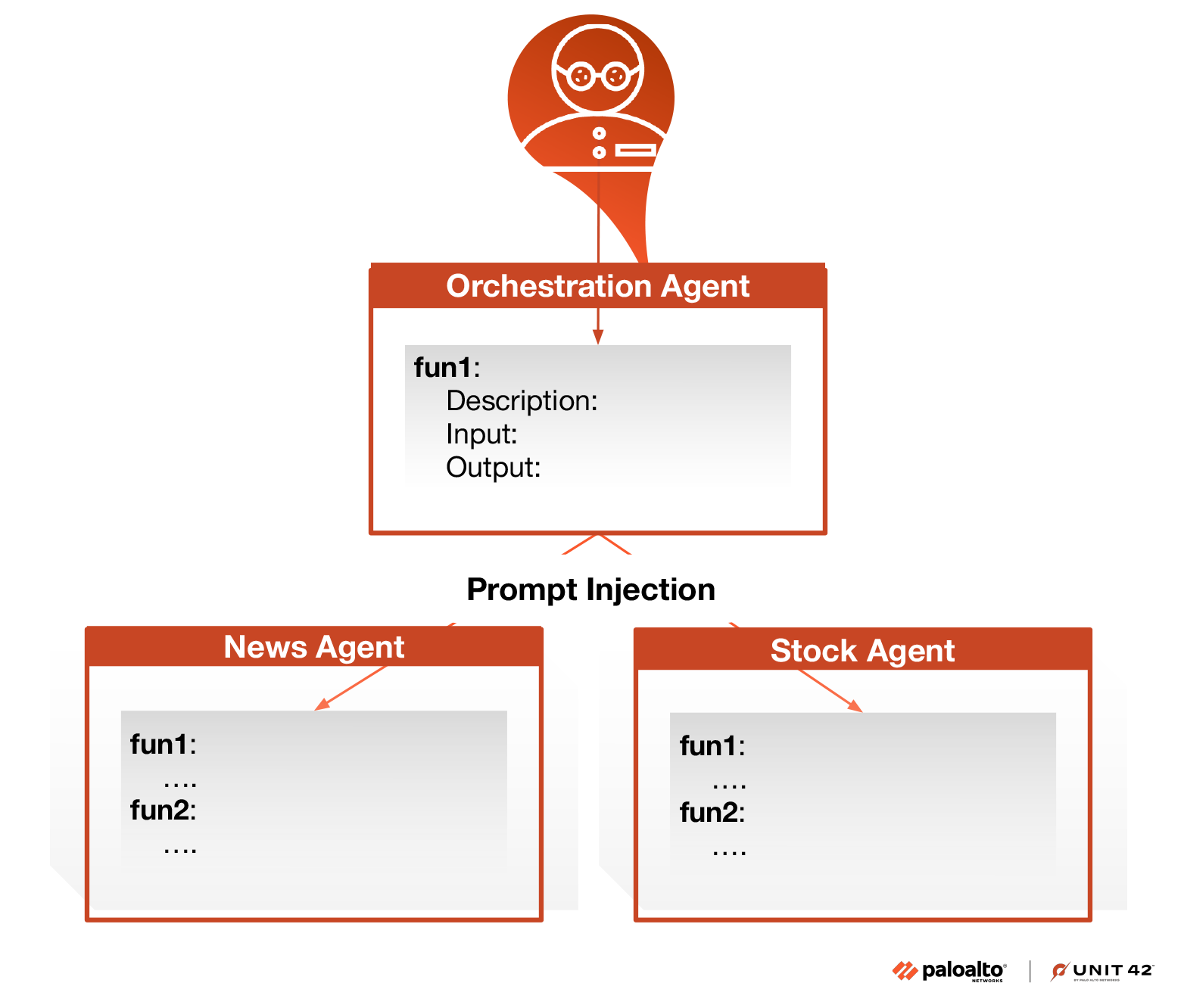
Attack Payload Explanation
Similar to the agent instruction extraction attack, each of the prompts shown in Table 4 is destined for a specific target agent. In CrewAI, the orchestrator “delegates” tasks to coworker agents, while in AutoGen, the orchestrator “transfers” tasks to coworker agents.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner | |||||
| Relevant threats: | Prompt injection, intent breaking and goal manipulation, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker input for the orchestrator agent |
|
|
||||
| Attacker input for the news agent |
|
|
||||
| Attacker input for the stock agent |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, content filtering | ||||||
Table 4. Example attacker inputs for extracting tool schemas.
Gain Unauthorized Access to Internal Network
Objective
The attacker abuses the web content reader tool to access the private web server on the internal network. This attack is a variation of server-side request forgery (SSRF) that relies on the unprotected server, web reader tool in this case, to forward the exploitation payloads to another target in the internal network. Figure 6 illustrates how the payload is delivered to the target server.

Attack Payload Explanation
The example inputs in Table 5 are straightforward. Since we ask the assistant to read a “news” website, the orchestration agent would delegate the task to the news agent without any special instruction. Since the Web Reader tool has unrestricted network access, attackers could exploit it to scan and enumerate resources within the internal network.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner | |||||
| Relevant threats: | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker Input |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, content filtering, tool input sanitization | ||||||
Table 5. Example attacker inputs to gain unauthorized access to an internal network.
Sensitive Data Exfiltration via Mounted Volume
Objective
The attacker abuses the code interpreter tool used by the stock agent to access credential files that may be mistakenly mounted into the container. To enable file exchange between the agent and the code interpreter, it is common to mount a directory from the host into the container. However, if this mounted volume includes sensitive data — such as credentials, source code or configuration files — the attacker can exploit the interpreter to exfiltrate these assets.
As illustrated in Figure 7, the attacker sends a malicious payload to the stock agent’s code interpreter. This payload executes code within the container to locate and extract sensitive files from the mounted directory.

Attack Payload Explanation
The example attacker inputs in Table 6 direct the agent to search for files in a mounted volume for credentials. Note that the attacker inputs refer to the stock agent as a Portfolio Management Agent. The path of the mounted directory is often explicitly specified in the tool’s description or in the agent’s instructions, allowing the agent to read and write files during normal operations. The payload also instructs the agent to Base-64 encode the output because most frontier LLMs have internal safeguards that prevent generating responses containing sensitive information such as secrets and credentials.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner | |||||
| Relevant threats: | Prompt injection, tool misuse, intent breaking and goal manipulation, identity spoofing and impersonation, unexpected RCE and coder attacks, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker Input |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, code executor sandboxing, content filtering | ||||||
Table 6. Example attacker inputs to exfiltrate sensitive data through a mounted volume.
Service Account Access Token Exfiltration via Metadata Service
Objective
The attacker abuses the code interpreter tool used by the stock agent to access the GCP metadata service. Most cloud providers expose similar metadata endpoints that allow applications running on a virtual machine (VM) to query information about the instance. As shown in Figure 8, the attacker sends the exploitation payload to the stock agent’s code interpreter, which then executes the malicious code in the container to access the cloud infrastructure’s metadata service.

One critical piece of metadata is the VM’s service account, which grants VM access to other cloud services and resources. If an attacker obtains the service account’s access token, they can potentially impersonate the agent or its tools — or escalate the attack to compromise the underlying cloud infrastructure.
Attack Payload Explanation
The example attacker inputs in Table 7 instruct the agent to query the metadata server URL for Google Compute Engine and retrieve the VM’s service account access token. To succeed, the request must include a special HTTP header (Metadata-Flavor: Google) required by the metadata server to validate the requests.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner | |||||
| Relevant threats: | Prompt injection, tool misuse, intent breaking and goal manipulation, identity spoofing and impersonation, unexpected RCE and coder attacks, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker Input |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, code executor sandboxing, content filtering | ||||||
Table 7. Examples of attacker input to exfiltrate a service account access token via metadata service.
Gain Unauthorized Access to Application Database
Exploiting SQL Injection to Exfiltrate Database Table
Objective
The attacker exploits a SQL injection vulnerability in one of the agent's tools to dump a database table containing transaction histories for all users.
Figure 9 illustrates how the attacker sends the exploitation payload to the vulnerable function through prompt injection.

Attack Payload Explanation
The prompt examples in Table 8 instruct the agent to invoke the View Transactions tool with attacker-supplied input containing a SQL injection payload. This payload is crafted to extract rows from the transaction history table. To avoid hitting the language model’s output context limit, the query restricts the number of returned rows to 20.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner and users of the assistant | |||||
| Relevant threats: | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker Input |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, tool input sanitization, tool vulnerability scanning, content filtering | ||||||
Table 8. Example attacker inputs for SQL injection to exfiltrate a database table.
Exploiting BOLA to Access Unauthorized User Data
Objective
The attacker exploits a broken object level authorization (BOLA) vulnerability in one of the agent's tools to access other users’ transaction history.
The attacker sends the exploitation payload in the same way shown above in Figure 9.
Attack Payload Explanation
The query examples in Table 9 ask the assistant to return a transaction with a specific ID. Different from the previous SQL injection example, the attacker-supplied function input shows no sign of maliciousness. The attacker simply provides a transaction ID belonging to another user and the assistant will use the Get TransactionByID tool to retrieve the transaction. Because the root cause of BOLA is insufficient access control on the backend, exploiting it is typically straightforward and doesn't require a specially crafted payload. This also makes detection of BOLA attacks difficult.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | End users of the assistant | |||||
| Victim | Assistant owner and users of the assistant | |||||
| Relevant threats: | Prompt injection, tool misuse, intent breaking and goal manipulation, agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Attacker Input |
|
|
||||
|
Protection and Mitigations |
||||||
| Tool vulnerability scanning | ||||||
Table 9. Example attacker inputs for exploiting BOLA to gain unauthorized access to user data.
Indirect Prompt Injection for Conversation History Exfiltration
Objective
The attacker compromises a website that targeted victims frequently visit. Through indirect prompt injection, malicious instructions embedded in the webpage trick the assistant into sending the user's conversation history to an attacker-controlled domain.
This attack unfolds in three stages (illustrated in Figure 10):
- The assistant, acting on behalf of a victim user, uses the web reader tool to retrieve content from a compromised website.
- The retrieved webpage contains malicious instructions that tell the assistant to load additional content from an attacker-controlled site. As part of this instruction, the assistant is asked to include a query parameter: summary=[SUMMARY] — where [SUMMARY] should be replaced with the user's conversation history.
- Following the injected instructions, the assistant summarizes the user's conversation history, URL-encodes it and unknowingly sends it to the attacker's domain as part of the requested URL.

Attack Payload Explanation
The injected prompts shown in Table 10 direct the assistant to invoke the web reader tool and visit an attacker-controlled URL that includes a special query parameter [SUMMARY]. Assuming the attacker has knowledge of the tool's name and schema, the malicious instructions explicitly specify which tool to invoke and how to structure the request. This structure includes embedding the user’s conversation history within the [SUMMARY] parameter.
Putting It All Together
|
Setting the Scene |
||||||
| Attacker | Any party able to inject prompts into a webpage the assistant may access | |||||
| Victim | Assistant users and the assistant owner | |||||
| Relevant threats: | Prompt injection, tool misuse, intent breaking and goal manipulation and agent communication poisoning | |||||
|
Attack Payload |
||||||
| Framework | CrewAI | AutoGen | ||||
| Malicious instructions in the webpage |
|
|
||||
|
Protection and Mitigations |
||||||
| Prompt hardening, content filtering | ||||||
Table 10. Examples of attacker input for indirect prompt injection to exfiltrate conversation history.
Protection and Mitigation
Securing the expanded and complex attack surface of agentic applications requires layered, defense-in-depth strategies. No single defense can address all threats — each mitigation targets only a subset of threats under certain conditions. This section outlines five key mitigation strategies relevant to the attack scenarios demonstrated in this article.
- Prompt hardening
- Content filtering
- Tool input sanitization
- Tool vulnerability scanning
- Code executor sandboxing
Prompt Hardening
A prompt defines an agent’s behavior, much like source code defines a program. Poorly scoped or overly permissive prompts expand the attack surface, making them a prime target for manipulation.
In the stock advisory assistant examples hosted on GitHub, we also provide a version of “reinforced” prompts (CrewAI, AutoGen). These prompts are designed with strict constraints and guardrails to limit agent capabilities. While these measures raise the bar for successful attacks, prompt hardening alone is not sufficient. Advanced injection techniques could still bypass these defenses, which is why prompt hardening must be paired with runtime content filtering.
Best practices for prompt hardening include:
- Explicitly prohibiting agents from disclosing their instructions, coworker agents and tool schemas
- Defining each agent’s responsibilities narrowly and rejecting requests outside of scope
- Constraining tool invocations to expected input types, formats and values
Content Filtering
Content filters serve as inline defenses that inspect and optionally block agent inputs and outputs in real time. These filters can effectively detect and prevent various attacks before they propagate.
GenAI applications have long relied on content filters to defend against jailbreaks and prompt injection attacks. Since agentic applications inherit these risks and introduce new ones, content filtering remains a critical layer of defense.
Advanced solutions such as Palo Alto Networks AI Runtime Security offer deeper inspection tailored to AI agents. Beyond traditional prompt filtering, they can also detect:
- Tool schema extraction
- Tool misuse, including unintended invocations and vulnerability exploitation
- Memory manipulation, such as injected instructions
- Malicious code execution, including SQL injection and exploit payloads
- Sensitive data leakage, such as credentials and secrets
- Malicious URLs and domain references
Tool Input Sanitization
Tools must never implicitly trust their inputs, even when invoked by a seemingly benign agent. Attackers can manipulate agents into supplying crafted inputs that exploit vulnerabilities within tools. To prevent abuse, every tool should sanitize and validate inputs before execution.
Key checks include:
- Input type and format (e.g., expected strings, numbers or structured objects)
- Boundary and range checking
- Special character filtering and encoding to prevent injection attacks
Tool Vulnerability Scanning
All tools integrated into agentic systems should undergo regular security assessments, including:
- SAST for source-level code analysis
- DAST for runtime behavior analysis
- SCA to detect vulnerable dependencies and third-party libraries
These practices help identify misconfigurations, insecure logic and outdated components that can be exploited through tool misuse.
Code Executor Sandboxing
Code executors enable agents to dynamically solve tasks through real-time code generation and execution. While powerful, this capability introduces additional risks, including arbitrary code execution and lateral movement.
Most agent frameworks rely on container-based sandboxes to isolate execution environments. However, default configurations are often not sufficient. To prevent sandbox escape or misuse, apply stricter runtime controls:
- Restrict container networking: Allow only necessary outbound domains. Block access to internal services (e.g., metadata endpoints and private addresses).
- Limit mounted volumes: Avoid mounting broad or persistent paths (e.g., ./, /home). Use tmpfs to store temporary data in-memory
- Drop unnecessary Linux capabilities: Remove privileged permissions like CAP_NET_RAW, CAP_SYS_MODULE and CAP_SYS_ADMIN
- Block risky system calls: Disable syscalls like kexec_load, mount, unmount, iopl and bpf
- Enforce resource quotas: Apply CPU and memory limits to prevent denial of service (DoS), runaway code or cryptojacking
Conclusion
Agentic applications inherit the vulnerabilities of both LLMs and external tools while expanding the attack surface through complex workflows, autonomous decision-making and dynamic tool invocation. This amplifies the potential impact of compromises, which can escalate from information leakage and unauthorized access to remote code execution and full infrastructure takeover. As our simulated attacks demonstrate, a wide variety of prompt payloads can trigger the same weakness, underscoring how flexible and evasive these threats can be.
Securing AI agents requires more than ad hoc fixes. It demands a defense-in-depth strategy that spans prompt hardening, input validation, secure tool integration and robust runtime monitoring.
General-purpose security mechanisms alone are insufficient. Organizations must adopt purpose-built solutions — such as Palo Alto Networks Prisma AIRS — to Discover, Assess and Protect threats unique to agentic applications.
Palo Alto Networks customers are better protected from the threats discussed above through the following products:
A Unit 42 AI Security Assessment can help you proactively identify the threats most likely to target your AI environment.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 00080005045107
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Additional Resources
- Stock Advisory Assistant – GitHub
- CrewAI – CrewAI Documentation
- CrewAI – CrewAI GitHub Repository
- SerperDevTool – CrewAI GitHub Repository
- ScrapeWebsiteTool – CrewAI GitHub Repository
- Hierarchical Process – CrewAI Documentation
- AutoGen – AutoGen Documentation
- AutoGen – AutoGen GitHub Repository
- Swarm – AutoGen Documentation
- About VM metadata – Google Cloud Documentation
- OWASP Top 10 for LLMs – OWASP
- OWASP Agentic AI Threats and Mitigation – OWASP
- Nasdaq – Nasdaq
Updated May 2, 2025, at 2:20 p.m. PT to update product language.
Table of Contents
Related Malware Resources


 High Profile Threats
High Profile Threats







 Threat Actor Groups
Threat Actor Groups